








When we ask ChatGPT or any AI assistant a question, it sometimes provides a wrong or outdated answer. This happens because AI models are trained on past data and may not always be aware of the latest information or documents from private companies.
This is where the RAG (Retrieval-Augmented Generation) architecture comes in. Think of it as giving your AI access to a library of up-to-date, custom documents and teaching it to look things up before answering, just like a smart student who checks notes before writing an exam answer.
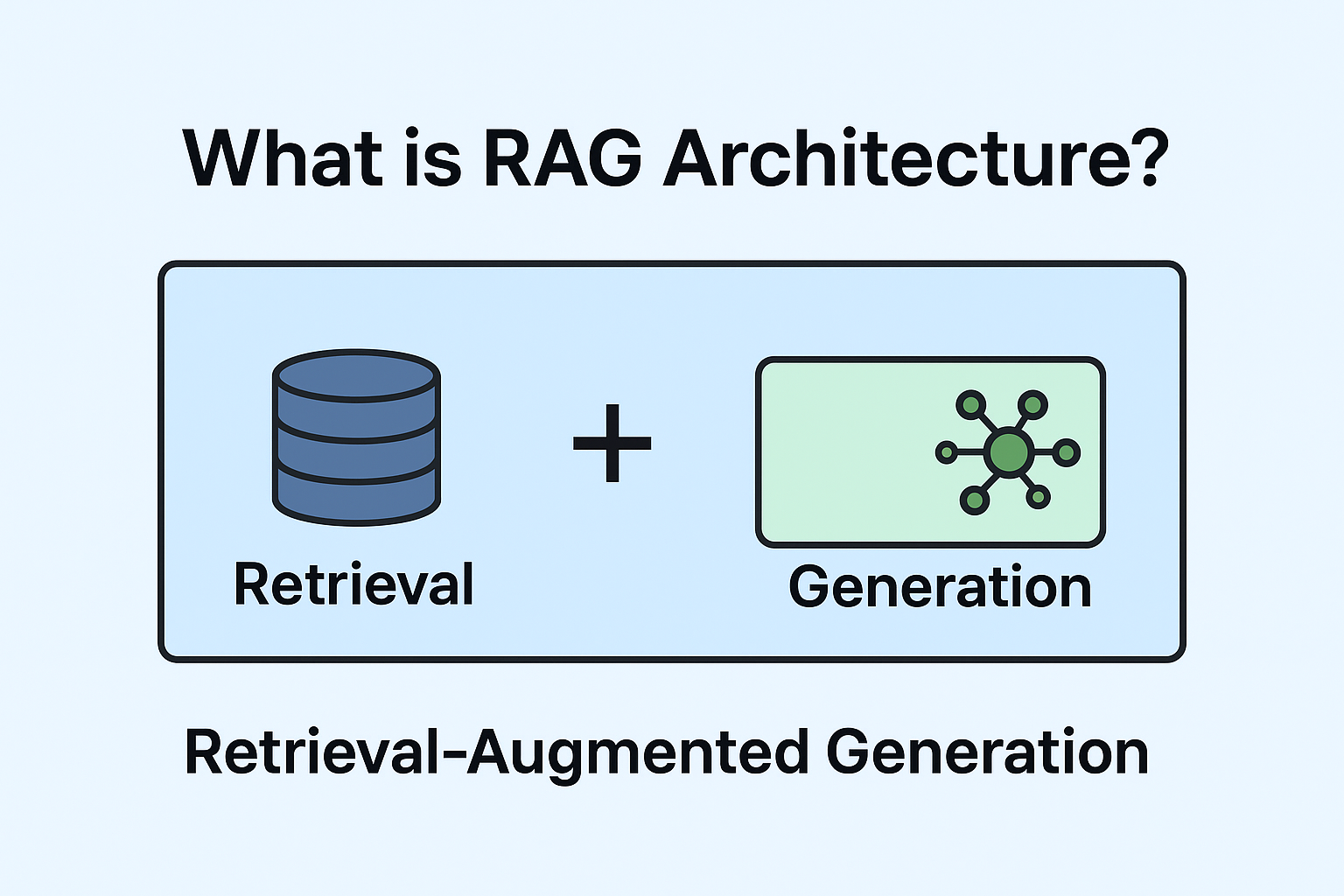
What is RAg in Simple words?
RAG stands for (Retrieval-Augmented Generation): Retrieval + Generation.
Retrieval – AI searches your documents or database to find the most relevant pieces of information.
Generation – AI then uses that information along with its language skills to create a natural, complete answer.
Example: If you ask, “What are the leave policies in my company?”, instead of guessing, the AI looks into your HR manual (retrieval) and then summarises the exact rules for you (generation).
Why it matters:
Reduces wrong answers (AI hallucinations).
In AI, hallucinations refer to cases where a model (like GPT or another LLM) produces an output that is factually incorrect, misleading, or completely made up—but presented in a way that sounds fluent and confident.
Keep responses updated with your latest business data.
Works with private data that the base AI model never saw during model training.
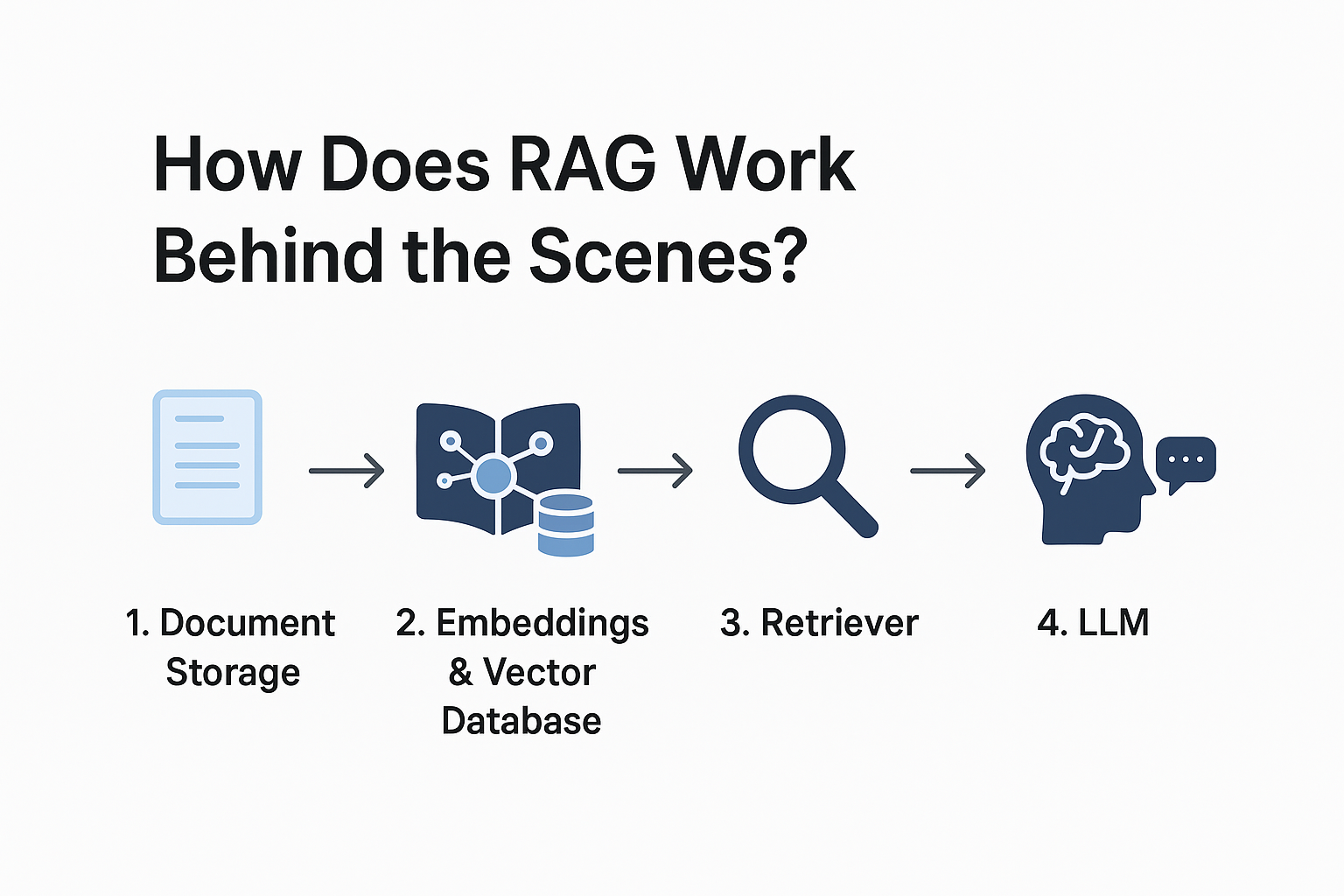
How does RAG work behind the scenes?
Step 1: Document Storage – Your data (PDFs, manuals, reports) is stored in the cloud.
Step 2: Embeddings & Vector Database – Text is converted into vectors (mathematical form) and saved in a vector database.
(Once embeddings are created for all your documents (PDFs, web pages, reports, etc.), they’re stored in a vector database like Pinecone, Weaviate, FAISS, or Milvus.
Unlike normal databases that do keyword matching, vector DBs use similarity search (cosine similarity, dot product, Euclidean distance).
That means:
If a user asks, “Tell me about healthcare policies in 2023,”
→ The system finds document chunks with embeddings closest to the query embedding (even if the words aren’t identical, the meaning matches).
Step 3: Retriever – When you ask a question, the retriever finds the most relevant document chunks.
Step 4: LLM (Large Language Model) – The AI (like GPT or Gemini) uses both the retrieved text + its own knowledge to answer you.
Implementing RAG in different Clouds
Retrieval-Augmented Generation (RAG) is becoming the standard way to make AI systems factual, up-to-date, and trustworthy. Instead of relying on an LLM’s “memory” (which can hallucinate), RAG lets the model pull verified knowledge from an external source like a database, document store, or enterprise data lake.
All three major cloud providers (AWS, GCP, Azure) now offer tools to help you build RAG systems. But the “how” depends a lot on which cloud you’re using. Let’s break it down.
1. AWS (Amazon web services): How AWS supports RAG
AWS offers a combination of Bedrock, OpenSearch, and Kendra for building RAG pipelines.
Amazon Bedrock lets you access LLMs (Anthropic Claude, AI21, Cohere, and more) without managing infrastructure.
Amazon Kendra is an intelligent search service that indexes enterprise documents and makes them searchable.
Amazon OpenSearch (or vector engines like Pinecone on AWS Marketplace) can store embeddings for similarity search.
Storage
Amazon S3 (Simple Storage Service) → Used to store raw documents like PDFs, text files, and images.
Amazon DynamoDB or RDS → Alternative structured storage.
Vector Database
Amazon OpenSearch Service (supports vector search).
Pinecone (via AWS Marketplace).
Weaviate / Milvus (containerised on AWS EKS).
Embeddings
Amazon SageMaker JumpStart models (e.g., sentence transformers).
Bedrock partner models (Anthropic, Cohere, and AI21 can generate embeddings).
Open-source embedding models deployed on SageMaker.
Example Agent & Use Case
Agent: An HR Assistant Agent for a large enterprise.
Employees upload HR documents into S3.
Text chunks are converted into embeddings using AWS SageMaker JumpStart models.
Embeddings are stored in OpenSearch.
Queries go through Kendra for semantic retrieval.
The LLM in Bedrock generates a grounded answer.
Employee Query: “What’s the maternity leave policy in India?”
Agent Answer (via RAG): “According to the HR policy, employees are entitled to 26 weeks of maternity leave in India (Source: HR Handbook, 2023).”
2. GCP (Google cloud Platform): How GCP supports RAG
Google Cloud has strong AI/ML foundations with Vertex AI.
Vertex AI Matching Engine provides large-scale vector search.
BigQuery can serve as the knowledge base.
PaLM 2 (via Vertex AI Generative AI Studio) is the LLM generator.
Document AI can process unstructured documents (PDFs, scans) and convert them into embeddings.
Storage
Google Cloud Storage (GCS) → For raw files like docs, CSVs, and PDFs.
BigQuery → Structured storage + querying for tabular data.
Vector Database
Vertex AI Matching Engine → Google’s native vector database for high-scale similarity search.
AlloyDB (Postgres with vector extensions).
FAISS (open-source, deployable on GCP).
Embeddings
Vertex AI Embeddings API (powered by PaLM models).
TensorFlow Hub or Sentence-BERT deployed on GCP AI Platform.
Can also use OpenAI embeddings via API, but hosted on GCP.
Example Agent & Use Case
Agent: A Healthcare Knowledge Agent for a hospital network.
Medical research papers and patient guidelines are stored in Cloud Storage.
Document AI extracts structured text from PDFs.
Text is embedded and stored in the Vertex AI Matching Engine.
A doctor asks: “What are the latest recommendations for treating Type 2 Diabetes?”
The retriever pulls the latest research paper snippets from 2023.
PaLM 2 generates a grounded summary.
Why should businesses care about RAG?
Because it makes AI practical and trustworthy. Imagine:
Customer support bots that give correct policy answers.
Medical assistants who provide accurate, updated research.
Legal or HR assistants who stick to your company’s rules.
Without RAG, AI risks sounding smart but being wrong. With RAG, it becomes reliable, fact-based, and enterprise-ready.
Final Thoughts
RAG architecture is one of the most important building blocks for modern AI architecture. It turns general-purpose AI models into specialised assistants powered by your own data.
Use AWS if you want enterprise scalability and already use its cloud.
Use GCP if you want the latest AI tools and Google’s Gemini.
Use Azure if your business runs on Microsoft 365 and you want GPT integration.
In short, RAG bridges the gap between AI’s knowledge and your real-world data.
Join AIAgentFabric today to discover, register, and market your AIAgents.